What's wrong with changing the scenarios to enable automation?

I’m continuing to answer questions that were asked during my session “Are BDD and test automation the same thing?” at the Automation Guild conference in February 2021. This is the third of five posts.
- Why should automation be done by the dev team?
- Isn’t the business-readable documentation just extra overhead?
- What’s wrong with changing the scenarios to enable automation?
- Can all testing be automated?
- How can Cucumber help us understand the root causes of failure?
The question
Why many times I find myself changing the BDD statements once I start automation, as there is certain information needed between steps? BDD framework is supposed to involve many stakeholders and yet I feel the statements are to be written in a very stringent fashion.
This is a question that gets right to the heart of the tension between specification and automation. Gáspár Nagy and I wrote Formulation to focus on the art of writing good executable specifications. One of the core messages, which warrants its own section, is that “readability trumps ease of automation”.
I’ll be describing some automation techniques while answering this question. There’s a wide variety of languages that are available for automating specifications, but I’ve chosen to write the examples using Java. The techniques are applicable no matter what language you use for automation.
Readability
The goal of business-readable specifications is to facilitate and encourage collaboration between the business team and the delivery team. Over many years, we have identified six properties that we believe most scenarios should conform to – and captured them in a five-letter acronym: BRIEF.
| Name | Meaning | |
|---|---|---|
| B | Business language | Business terminology aids cross-discipline collaboration |
| R | Real data | Using actual data helps reveal assumptions and edge cases |
| I | Intention revealing | Describe the desired outcomes, rather than the mechanism of how they are achieved |
| E | Essential | Omit any information that doesn’t directly illustrate behaviour |
| F | Focused | Each scenario should only illustrate a single rule |
| Brief | Shorter scenarios are easier to read, understand and maintain |
The benefits of business-readable specifications are numerous (and covered in a previous post), but two of the BRIEF properties are worth expanding on.
Focused
The majority of scenarios exist to clarify and illustrate how one business rule is expected to behave when implemented. Every application is made up of many thousands of interacting business rules, so we decompose specifications into the individual rules and illustrate each rule with one or more scenarios. These are called illustrative scenarios.
There is also value in scenarios that cover the interactions of multiple rules, or even a complete user journey. These are called journey scenarios and will not be covered in this article.
Essential
When we write an illustrative scenario, we need to constrain ourselves to presenting the reader with information that is pertinent to the rule being illustrated. Any information that doesn’t contribute to a reader’s understanding of how the rule should behave is incidental and inessential.
It is very tempting to include information that is necessary for the application to work even if that information does nothing to clarify the specific behaviour of the rule being illustrated. If we give in to this temptation, there are a couple of bad side effects:
- It’s harder to read the specification – more data is being presented and it’s not clear which data is essential to the rule’s behaviour
- The specification becomes more brittle – the scenario may need to be changed when some part of the application unconnected to the rule that it illustrates changes
Automation
Once the team has formulated a scenario to conform to the BRIEF properties, it should be our aim to automate it without having to introduce inessential information. There are many approaches and techniques to automate any scenario without having to change the text in any way. Here I present a high level overview of a few of them.
Passing data between steps
Every implementation of Cucumber has a mechanism for passing data between steps.
- Cucumber Ruby and JavaScript use a World object which each step can interact with to attach or access information. Many other flavours of Cucumber use a similar mechanism.
- Cucumber Java uses dependency injection (DI) to share a single instance of an object between different step definition classes.
- SpecFlow supports multiple mechanisms for sharing data.




What all implementations have in common is that the shared data is deleted after each scenario. This is to ensure that scenarios run in isolation and can’t affect each other. The obvious benefit is that you can run any scenario on its own, or any set of scenarios in any order, and the results should always be the same.
If you use mechanisms for sharing data or make state changes that persist after the end of a scenario (such as not rolling back database changes), then you can get unexpected test results. Cucumber has mechanisms that allow you to initiate setup and teardown activities at scenario boundaries, but it is the developer’s responsibility to remember to do this.
Behaviour midway through a user journey
Most scenarios should be illustrative scenarios (as described above), and the rule they illustrate will often only be relevant at specific points on a user journey.

It may seem reasonable to preface the scenario with all the steps required to get to the checkout page, but none of that information would help clarify the expected behaviour of the rule. Instead, there are at least three ways that the Given step of this scenario could be automated as it’s written (I’m assuming we’re dealing with a web application):
- End-to-end
- Use Selenium (or similar) to add products to the basket, and navigate to the checkout page
- A test double of the payment provider service or pre-allocated test card details would typically be used
- The DOM would be inspected to verify that the expected message was shown
- Service/API level
- Send HTTP requests to add products to the basket
- A test double of the payment provider service or pre-allocated test card details would typically be used
- The response payload would be inspected to verify that the expected message was returned
- Component/class level
- Call method(s) on the relevant class(es) to add products to the basket
- A test double of the payment component would return indicating success when called to authorise payment
- The return value of the relevant method call would be compared to the expected value
Each of these approaches avoids the need for the scenario to contain inessential information, while allowing the team to decide the appropriate automation technique to get the desired speed of feedback and level of confidence.
Aslak Hellesøy and the Cucumber team regularly structure their automation code so that a scenario can be executed at any of these levels without altering the text of the scenario.
Automating at the bottom of the pyramid
The test automation pyramid is a popular metaphor documenting a popular and successful strategy. I recommend you read this article even if you are fully aware of the metaphor already.
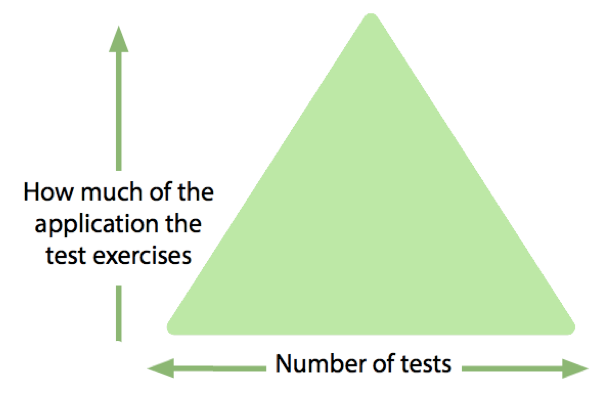
In the previous section, the three approaches described live at different levels of the pyramid:
- Component/class – near the bottom
- the detail of our code is verified using plentiful, small, fast tests
- mostly come for free with test driven development (TDD)
- Service/API – somewhere in the middle
- interaction and communication between dependent components is verified using test doubles, virtualisation, and contract tests
- these tests should be less interested in the actual data than in the categories of data that are being passed e.g., null, empty, zero/positive/negative, errors & exceptions
- End-to-end – near the top
- some user journeys automated to verify that functionality is available as expected
- also useful as smoke tests to ensure that deployment to an environment has been successful
Beth Skurrie has noted another variation as you move up the pyramid:
"... the more code the test covers, the lighter the touch of the test should be ... it's easy to fall into the trap of asserting more the more code a test covers, when it's much more maintainable to be asserting less, or at least, making more flexible assertions."
You’ll notice that I haven’t mentioned Behaviour-Driven Development (BDD) at all in this section. That’s because choosing whether to use developer test tools (e.g., JUnit) or natural language automation tools (e.g., Cucumber) depends on who will get value from reading the specification. So, choosing where in the pyramid you should automate should not be influenced by whether you’re using Cucumber or not. I go into this in more details in this article.
Invisible initialisation
Many of your scenarios will require some level of setup, no matter where in the pyramid they are automated. Even if that setup is not essential information for someone reading the specification, you’ll still need to find a mechanism to make sure it happens.
Examples of initialisation include:
- spinning up a local webserver or in-memory database
- restoring persistent test data to a known state
- creating and injecting test doubles/mocks/stubs
It’s rare that these activities should be included in a scenario. I’d also recommend that they don’t belong in a feature file at all, so should not be part of a Background.
Techniques that I’ve found useful are:
- Cucumber (conditional) hooks
- all Cucumber implementations have Before and After hooks that are called before or after a scenario runs
- some implementations have additional hooks, such as BeforeStep/AfterStep and BeforeAll/AfterAll
- hooks can be made conditional on the tags applied to the currently running scenario
- this is the default approach that should be considered first
- tags are part of the specification, so should always make sense to business colleagues
- Proxy/surrogate design pattern
- access the resource through a proxy, that will create it when first needed
- this approach should be considered when
- there is occasional need for an object to be created
- the creation is expensive, and
- it is not otherwise possible to localise the object’s use
- Instance variable (for Cucumber’s that support DI)
- access the resource through an instance variable on an injected shared object
- the injected shared object can also defer resource creation until first access
- Cucumber will only create the shared object when execution requires a step definition that requires it
- access the resource through an instance variable on an injected shared object
An entity may be essential for correct running of an automated test, without being an essential ingredient of a specification whose purpose is to illustrate and clarify a business rule. These three initialisation techniques will enable you to preserve the business value of the specification, without causing an excessive burden on the automation.
Data builders
Not all objects are simple to build. They may have many properties – some of which need to be manipulated to illustrate a specific rule, such as a customer that may require name, address, gender, date of birth. For scenarios where the value of these properties is unimportant, we should not need to specify them. For scenarios where it is necessary to set a specific value for only one of these properties, we should be able to do it in a way that preserves the need to only include essential information in the scenario.

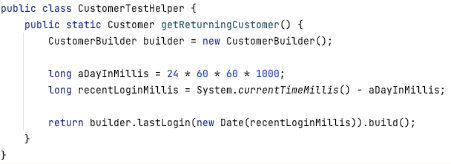
The Builder pattern supports easy creation of complex objects, typically by offering:
- A default object which can be used when specific values are not required
- Overrides to set specific values for selected properties
- Named objects (personas) that represent well defined sets of values (e.g., overdrawn account, domiciled overseas etc.)
This approach will also work for objects that are the root of a network of connected objects, such as a customer that has multiple accounts.
Conclusion
Once the formulated wording of a scenario has been agreed between business and delivery, it should not be changed unless either the business requirement it illustrates changes, or an essential omission or error is found. It should certainly not be modified to make the process of automation easier.
In this article, I have given an overview of five core techniques that can help simplify automation. Some of them are foundational techniques applied across all types of test automation, while others are more specific to the automation of Cucumber/SpecFlow step definitions.