Cucumber is a tool that understands feature files written using the Gherkin (Given/When/Then) syntax and calls automation code in response to each line it finds. These feature files become living documentation for the application you’re building, because each scenario in the feature file either passes or fails – meaning that you will always know if your documentation accurately describes your application’s behaviour.
One of the most useful formats that Cucumber outputs the documentation in is HTML. This means that organisations can upload the living documentation to a Wiki or website each time Cucumber runs. However, organisations have found that this leads to a number of challenges that need to be solved.
Behaviour-driven development (BDD) is the collaborative software development approach that Cucumber was built to support. If you’d like to know more about the Cucumber Open source project take a look at the documentation. If you’d like to learn more about BDD, we have free online courses available at Cucumber School.
|
Cucumber Reports
Even with Cucumber's HTML output, it's still not trivial to share Cucumber test results with your colleagues. To simplify this, the Cucumber team has developed a free, cloud-based service for sharing reports throughout the organisation. Currently in an early beta, the Cucumber Reports service allows you to configure Cucumber (Ruby or Java flavours only at the moment) to upload the results of a Cucumber run to the cloud. You can then access them from your browser, where they will be rendered using the same HTML formatter that would be used on the desktop.
The public beta is available at https://reports.cucumber.io where you will find a sample report and an FAQ. There are also some high-level instructions (as shown in the screenshot below). For more detailed instruction, read on.

NOTE: You'll need Cucumber-Ruby: 5.0.0 or Cucumber-JVM 6.5.0 (or later) to be able to access the publish functionality.
A quick tutorial
When you run Cucumber, the console output will have a message appended:
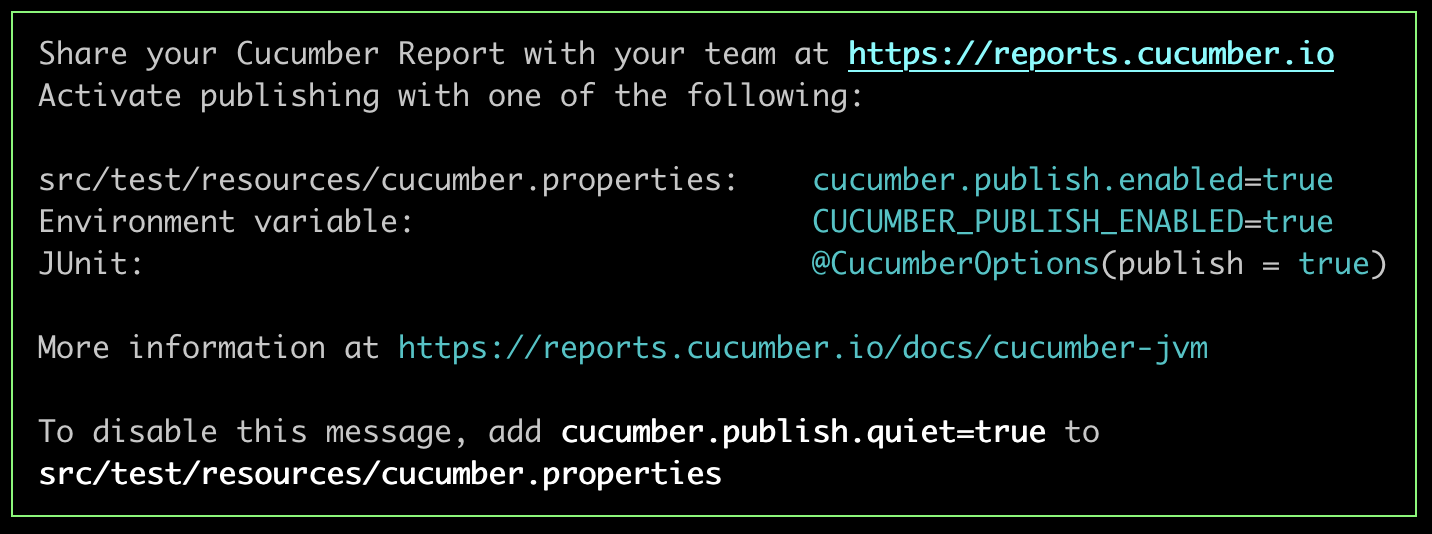
[Cucumber-JVM output]
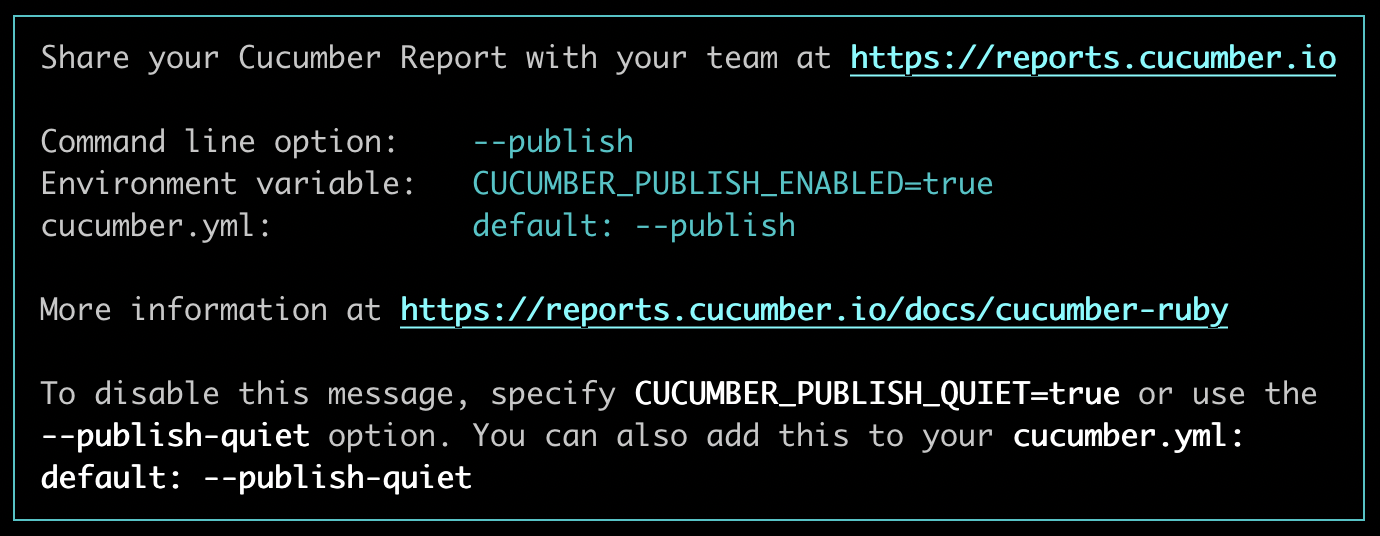
[Cucumber-Ruby output]
The easiest way to try out the publishing with Cucumber-JVM is with configuration in src/test/resources/cucumber.properties. Open (or create) the file and add the following line:
cucumber.publish.enabled=true
The easiest way to try out the publishing with Cucumber-Ruby is to specify the --publish option when you invoke Cucumber: cucumber --publish
Now, when you run Cucumber, you get a different console message:

If you follow the link, you'll see your report rendered in glorious colour (including any screenshots attached by a call to the attach function from your step definitions). We know that the styling isn't perfect yet - we're iterating on it, so let us know your thoughts.
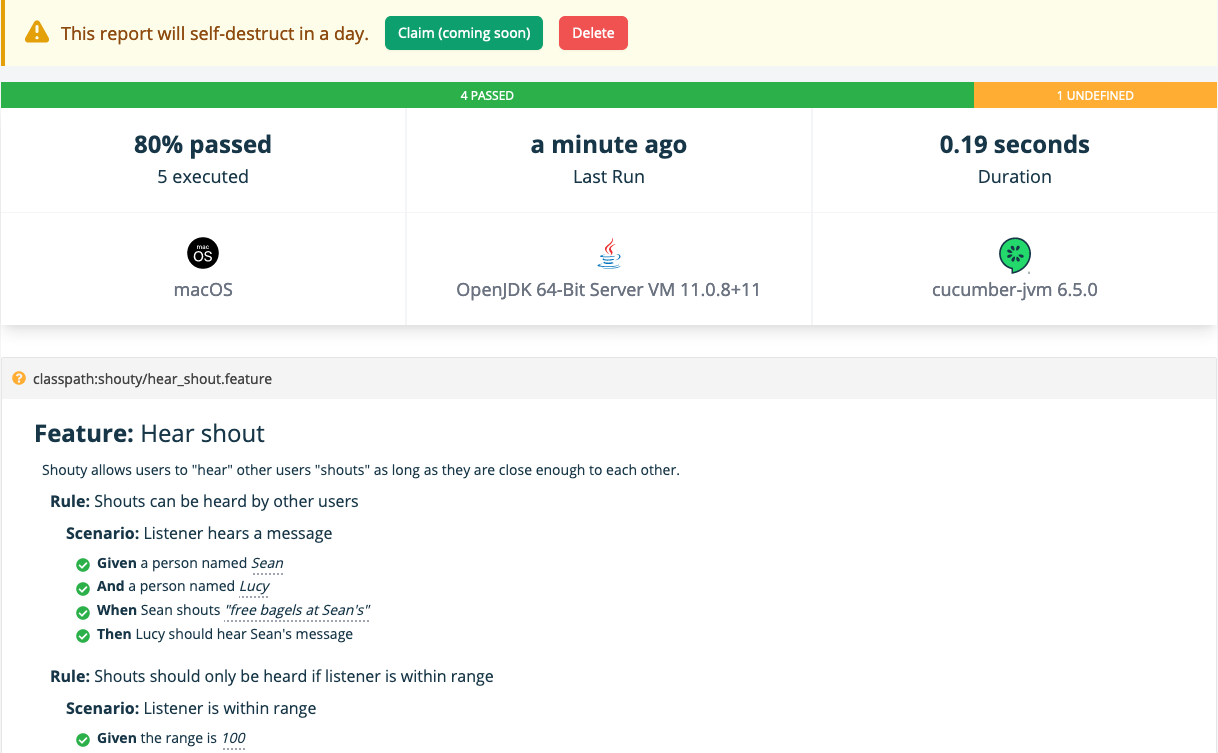
Share the link with your team members, so that you can all see the same report instantly.
Continuous Integration
If you run Cucumber from a supported Continuous Integration server, the report will be augmented with a fourth column displaying extra information about the CI server and the commit:

Claims, Authentication, and auto-delete
As the warning at the top of the page states, reports will be auto-deleted after 24 hours. This is because, at the moment, the report is secured only by the obscurity of the GUID generated when it is published. For now, don't publish reports that contain sensitive or confidential information.
Soon you will be able to link a report to a GitHub repository by claiming it. Once a report is claimed, it will only be accessible to the people with access to the linked GitHub repo, and it will no longer be scheduled for auto-deletion. When new reports are published, you will see them grouped under the same GitHub repository.
Any reports that have been published without being claimed can be claimed manually by clicking the Claim button before the 24 hour self-destruct countdown has completed. You can always delete a report by clicking the Delete button.
Tell us what's missing
Our aim is to enhance the Cucumber Report service with other tools that will provide additional value, such as:
- Private hosting - install your own Cucumber Reports service.
- Statistics - get an overview over how your scenarios evolve over time.
- Gherkin linting – apply rules and heuristics to offer advice about how to improve your feature files and scenarios.
- Unstable scenario identification – identify scenarios that flicker (sometimes passing, sometimes failing) for no apparent reason.
- Test case prioritisation – identify the critical scenarios that should be run to ensure fast feedback without increased risk of defects escaping.
These are some of the features that we’re considering implementing next, but we’d love to hear from you. What features would you like us to work on next?
Get in touch by: