BDD, approval testing, and VisualTest

This blog post explores the challenges of applying a Behavior-Driven Development (BDD) approach to UI development using VisualTest. In addition to giving a high-level introduction to BDD, I’ll describe a technique called Approval Testing that complements traditional assertion-based testing to give developers clearer visibility of the correctness of their implementation.
What is BDD?
BDD is an agile development approach in which three practices are applied to each story/backlog item: Discovery, Formulation, and Automation. Much has been written about BDD and there are many good introductory articles available, but here I’d like to stress that these practices must be applied in the correct order. Discovery, then Formulation, then Automation.
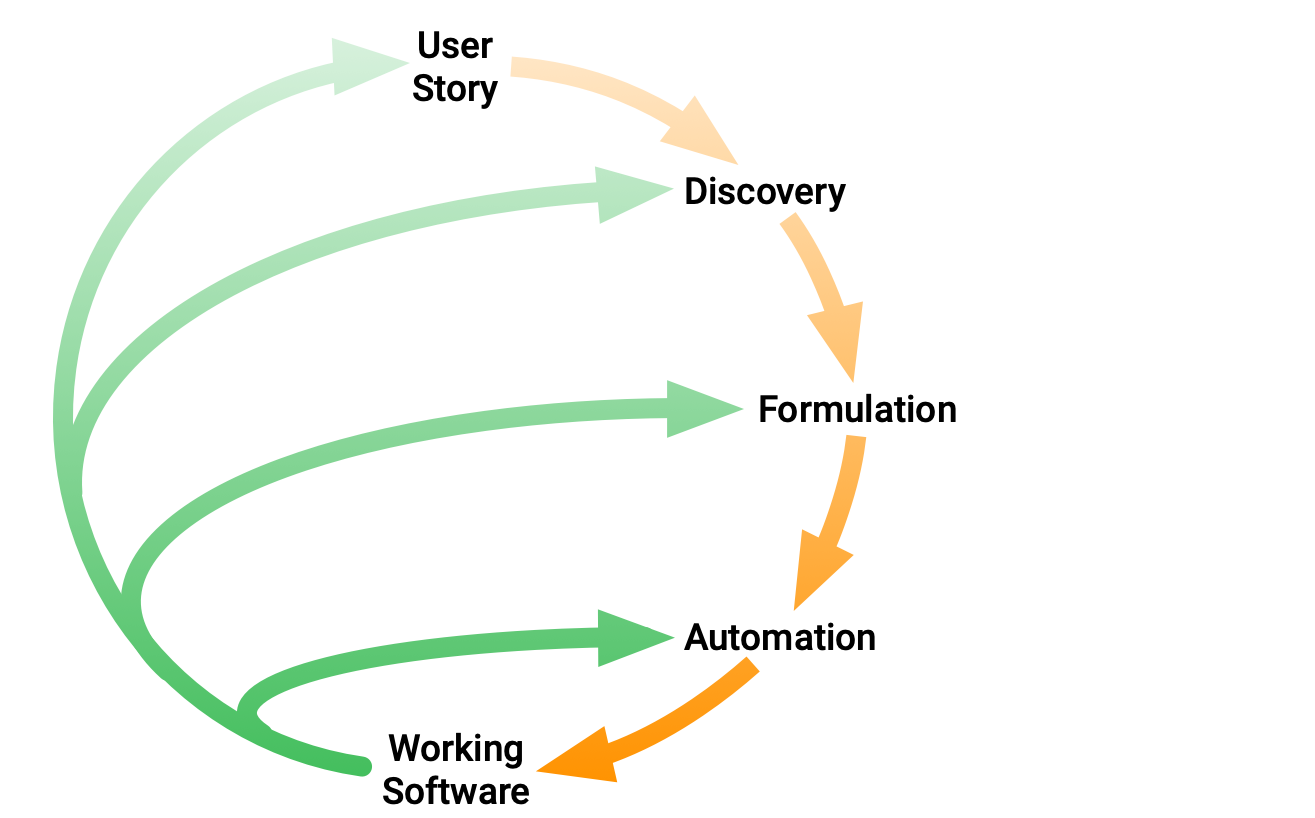
In the context of BDD, Automation means the writing of test code before the code under test has been written. Just like Test-Driven Development (TDD), the failing automated test drives the development of the production code. There are two implications of this approach:
- Every test should be seen to fail when it is written and seen to pass when the correct production code is implemented. Never trust a test that you haven’t seen fail.
- The automation code must be written either by the people who will write the production code or by someone who is collaborating very closely with them.
Should automation be end-to-end?
There’s a common misconception that all BDD scenarios will be automated end to end, exercising the entire application stack. Since each BDD scenario is only intended to specify a single business behavior, using an end-to-end approach for each one would be incredibly wasteful:
- Runtime – end-to-end tests take longer to run than tests that exercise specific areas of the code.
- Noise – the more of the code each test exercises, the more likely it is that many tests will all hit the same code paths. So, an error in that code path will cause all the tests that use it to fail, even if that part of the code has nothing to do with the business behavior the scenario was created to specify. In the face of multiple failing scenarios, it’s hard to diagnose which behavior has deviated from specification.
 https://cucumber.io/blog/bdd/eviscerating-the-test-automation-pyramid/
https://cucumber.io/blog/bdd/eviscerating-the-test-automation-pyramid/
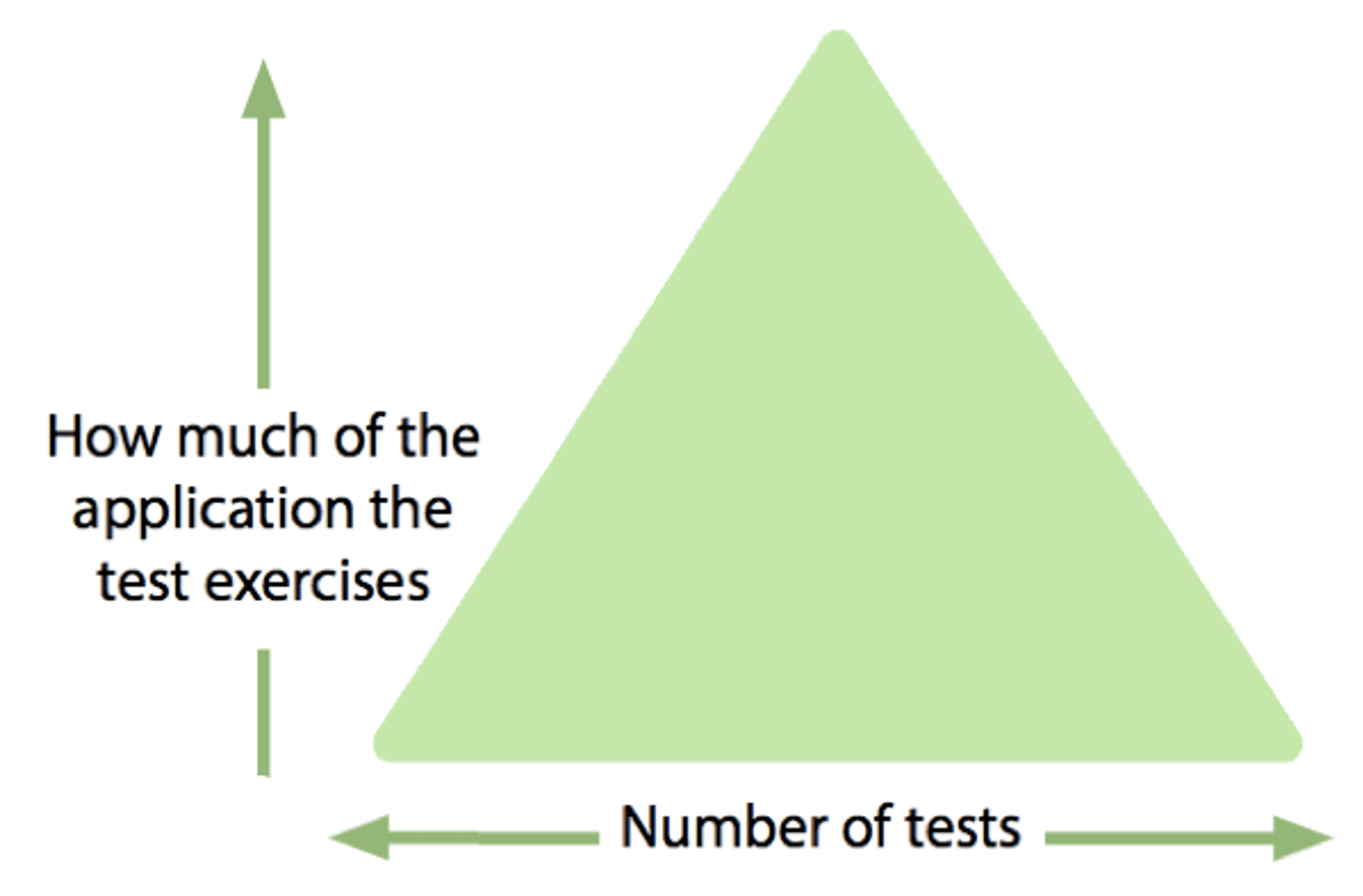
The Test Automation Pyramid is a common metaphor that suggests most tests should not be end to end. Applying this approach to BDD automation means that we should consider the most appropriate automation to ensure that a specific behavior has been implemented as specified.
How should the UI be tested?
BDD scenarios that describe how the UI should behave are usually written using tools such as Selenium. These can be slow and brittle because the UI is often tightly coupled with the rest of the application. However, conceptually, the UI is a component that interacts with other application components. It should therefore be possible to test the UI in isolation, near the bottom of the Test Automation Pyramid, by providing test doubles for the application components that it depends on.
Many applications are architected in such a way that the UI can only be exercised as part of an end-to-end test. Whenever possible, a more flexible architecture (that allows the UI to be exercised with the rest of the application “stubbed out”) should be preferred.
Is that all?
Even with a flexible architecture and automation that conforms to the Test Automation Pyramid, there are challenges. Most test frameworks come with simple assertion libraries that verify if text or numerical values are set as expected. If you need to validate all the fields in a report, you will need an assertion for each of them. This approach leads to verbose automation code that is time consuming to write and difficult to maintain. Additionally, as soon as one assertion fails, the whole test fails without checking any subsequent assertions.
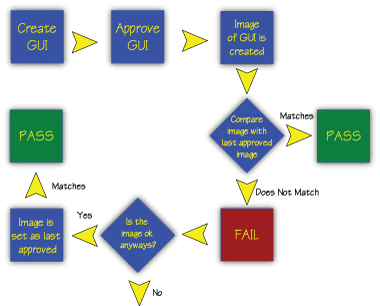
For many years, a technique called Approval Testing has been used in these situations, and several tools have been developed to help teams incorporate approval testing into their software development processes. The mechanics of how the tools work vary, but their approach is the same:
- The first time the test is run, the output is checked manually. If correct, this output is stored as the “approved” output. If not, fix the software and repeat until the output produced is correct.
- On subsequent test runs, the tool will compare the output produced to the “approved” output previously recorded. If they are found to be the same, then the approval test has passed. If not, the approval test has failed.
https://llewellynfalco.blogspot.com/2008/10/approval-tests.html
Naturally, it’s not quite as simple as that. For example, if the complex output that we’re comparing includes timestamps, these will likely be different each time the test is run. Therefore, approval testing tools typically include mechanisms to specify parts of the output that should not be compared. These exclusions will be specified when the approval test is first created and stored alongside the test.
Does approval testing work for UIs?
Simply specifying areas of the output that should not be compared is insufficient if we’re trying to automatically verify the correctness of a visual component. Perhaps a text field is now too close to the border of a control or one visual element is overlaying/obscuring another one.
In these situations, machine learning (ML) and artificial intelligence (AI) can deliver huge benefits. Our tests can leverage these technologies to identify these hard-to-spot issues to a precision that the human eye cannot. But they take time – and slow feedback from a build is the enemy of automated testing.
Instead, AI/ML powered visual tests should be run in a separate stage in the build pipeline, after the faster automated checks have already passed. This ensures that developers get the fast feedback they require while also delivering confidence that the UI is free of visual defects.
If the visual tests pass, then all is well. If there’s a failure during the visual tests, then manual investigation is required – because not all failures indicate a defect in the code.
When is a failure not a fail?
We normally think of a test as having a binary outcome. It either passes or fails. Life in software development is rarely that simple. To ensure that the software we ship satisfies our customers’ needs we want to minimize false positives. So, when a test passes, we need to be confident that the behavior being verified is implemented correctly.
When a test fails, it doesn’t necessarily mean that the behavior has been implemented incorrectly. In my experience there are three common situations that cause a test to fail:
- Incorrect implementation: this could be caused by a misunderstanding of the specification or an error in the implementation.
- Incorrect specification: the test is performing the wrong check(s) or the check(s) are being carried out incorrectly.
- BDD/TDD: the test has been written before the behavior it’s designed to check has been implemented.
When any sort of failure happens in a build, investigation is required. If you find that Situation 1 or 2 has occurred, fix the defect (either in the implementation or the specification) and run the build again.
Situation 3) is a signal to the development team that the work is incomplete. Seeing an automated test fail is an important part of all BDD/TDD workflows. Usually, we would like the failure to be seen in the developers’ environment and made to pass before being pushed to CI. However, some workflows may see the tests committed and pushed before the behavior being verified is implemented.
VisualTest – an AI/ML powered visual approval testing tool
There are several popular approval testing tools available (TextTest, ApprovalTests), but they lack the powerful AI/ML techniques that are needed for effective assurance of UIs and other graphical outputs. SmartBear provides a new tool that fills a gap that has long been overlooked in the full stack of UI testing - VisualTest.

https://smartbear.com/product/visualtest/
Conclusion
The development team need regular, fast feedback to give them visibility of important aspects of their software’s quality. They need confidence that they’re developing the right thing in the right way.
BDD and TDD are techniques that give developers that confidence (among other benefits). Currently, most organisations that adopt these approaches use popular assertion-based tools to verify that the code being developed satisfies the specifications. This focus on assertion-based testing is unsuitable for some of the subtle and complex issues that occur when developing today’s applications.
Approval testing in all its flavours can help bridge the gap between automated assertion checking and time-consuming manual testing. Existing approval testing libraries are excellent when dealing with complicated textual outputs and simple graphical components. VisualTest leverages AI/ML to fill that gap and bring approval testing for modern UIs within reach of reliable automated testing.