Please note: This blog post refers to an earlier version of Cucumber Pro, and describes features that are not part of the current version. Please refer to the current documentation for up-to-date information about Cucumber Pro's features, and how to join our early-access programme.
The post is left here as a historical record. For a trip down memory lane, read on.
Cucumber Pro is accessed via a regular browser or tablet. When you log in you will be presented with a list of your projects. If you don't have any projects you can add one by specifying the URL to a source control repository on GitHub, Bitbucket or Subversion.
When you open a project you will see a list of Feature files that you can open, edit and save. For more details about how the various features work, please refer to this blog post.
The diagram below gives a high level overview of the architecture, to give a better understanding of how Cucumber Pro fits in with other tools.
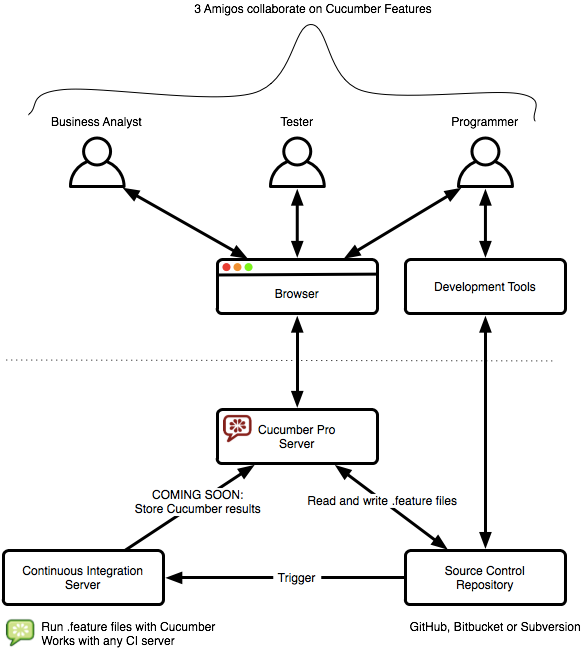
At the top you see the three typical roles of people using Cucumber Pro together to collaborate on Cucumber Features (Executable Specifications).
Cucumber Features are plain text files that are stored in your own source control repository. With Cucumber Pro several people can edit these files in a web browser. The editor offers autocompletion to help with editing. Users don't have learn how to use source control - the editor is easier to use than a word processor.
Cucumber Pro only stores files in your own source control repository. No copies are stored in Cucumber Pro itself.
Cucumber Pro does not execute your Cucumber Features. You should set up a Continuous Integration (CI) server to do that automatically whenever a Feature file is saved (or other code is pushed to your source control).
Cucumber Pro will soon be able to collect result from Cucumber running in a CI server and present reports based on those.