Solving: "How to organise feature files?"

Over the holidays you voted for different ways to organise feature files. This article shows the results of the survey, an analysis of the votes, and some general ideas on how to organise your living documentation.
Gojko Adzic has been running a series of challenges called #GivenWhenThenWithStyle. This is my solution to challenge #16. You should definitely check out the rest of the challenges and their solutions.
The winner is…
From the survey, splitting by functional area and grouping by capability was the runaway winner.
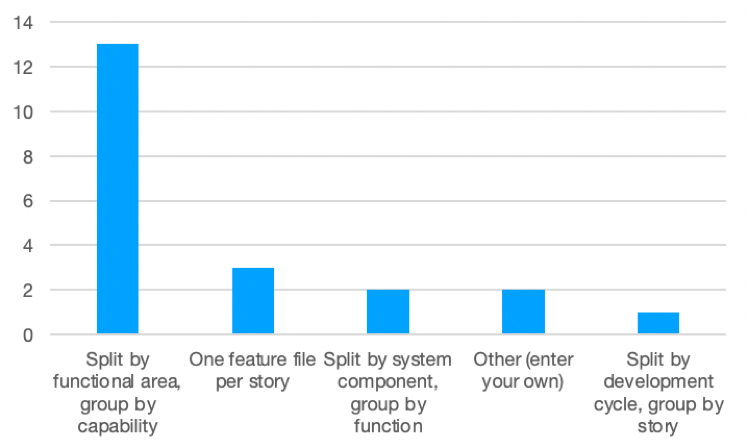
Regarding the “other”, Ken Pugh again posted a detailed response in which he suggests organising feature files in a functional hierarchy. I’ll dig into this in more detail later in this post.
Dhanunjay was one of three participants that chose the feature file per story solution, for ease of maintenance. Another participant chose split by system component because it gave “better visibility of test coverage”. I have very strong reservations about both of these rationales, which I explain below.
Matt Wynne was one of the participants that selected the winning option, with this succinct reason:
Because every one of the other options leaks solution domain; this is the only one that's pure problem domain.
This reason was echoed by other participants André, Marcel Kwakernaak, and Geert-Jan Thomas who all recognised the importance of feature files as business-facing documentation. I particularly like this comment, left by an anonymous participant:
The software that is developed is for business purpose, therefore ability to master business capability is prime over technical aspect. I like the idea of being able to quickly pin down system-components in question that generate issues, so a supporting structure that conveys which system-component is to "blame" is very welcome - typically I do this with tags and evaluate the test-reports based on tags…
More on tags later.
Specification or testing?
In my experience, the Given/When/Then format has two major drivers in industry:
- Specification of system behaviour
- Test automation
It was originally used as a way to specify the behaviour of systems. To automatically verify that the software being developed met those specifications, the Given/When/Then examples needed to be written in a format that automation tools could understand. This led to the creation of the Gherkin language, which defined a structured way to capture Given/When/Then specifications as scenarios in feature files. Gherkin enabled the creation of automation tools (such as JBehave, Cucumber, SpecFlow) that could read the specifications and execute automation code in response.
With the increased demand for test automation, Gherkin’s similarity to natural language was recognised as a way to enable test automation tasks to be performed by people that did not have software development skills.
The winning option for this challenge implicitly assumes that Gherkin is being used to specify system behaviour. The responses expect feature files to be used as documentation, throughout the lifetime of the product. This has always been the intention of Behaviour-driven development (BDD) and Specification by example (SbE).
The remainder of this solution will assume that you intend to use Gherkin to document system behaviour.
Features are documentation
Gherkin documentation is split into feature files, but there’s no standard definition of what a feature is. The Collins dictionary defines a feature as “an interesting or important part or characteristic,” and I don’t intend to try to be more specific.
To illustrate feature file organisation I’ll use diagrams below that relate to an imaginary online pizza ordering application (taken from our book, Formulation).
Navigating the documentation
There's nothing worse than trying to find a specific piece of information in poorly organized documentation, so feature files should be organised in a logical way. A typical way to structure documentation is to use chapters, sections, sub-sections and so on.
Each scenario documents an example of the system's behaviour. Scenarios live in feature files, which in turn live in source control, which is typically organised hierarchically. The feature files collectively document the behaviour of the system, but are only useful when people can easily navigate to the part that they are interested in. A hierarchical tree of folders provides a simple way to structure our documentation that is identical to traditional documentation.

Figure 1 - Traditional documentation
Consider a system that allows customers to order pizzas online. A partial view of the documentation might look like this:

Figure 2 – Online ordering
Zoom-in/out
A hierarchical structure also allows us to organise documentation by level of detail. The deeper the folder, the more fine-grained the behaviour described. Here's how the Customers hierarchy might actually look.

Figure 3 - Customers documentation
Even in a simple system, there are many levels of detail. Some readers will be looking for the big picture - they should not need to travel far from the root of the documentation. Others will be interested in specific details - they should be able to navigate to the relevant section easily.
This is similar to how we use online maps. We can get a good idea of where New York is relative to Washington without needing much detail. If we actually want to drive from one to the other, we will need to zoom in and get details about which route to take.
Specifying shared behaviours
You may have noticed a send_email.feature inside email confirmation. There may well be other features that send emails and we wouldn’t want to create a copy of that feature file wherever that functionality is used.
When we find a feature that is used by several parts of our system, we should ensure that a single feature file describes the behaviour. Then, if it needs to change, we only have to change the documentation in one place.

Figure 4 – Extracting shared email functionality
It's easy to move shared features into a separate part of the tree, but at the moment, there's no special way to link from one feature file to another in Gherkin. For now, I recommend that you document the dependencies of a feature in the feature file description. The best information to include is the name and relative file path of the:
Feature: Send unique link
This feature is dependent on:
- Send Email - ../../../communication/email/send_email.feature
Targeted documentation
There is another important aspect of documentation - different consumers require different information. To keep the documentation readable, we need to ensure that sales executives don't get forced to read API documentation, while integrators may not be interested in all the details of our application.
Depending on your situation, you may choose to create separate hierarchies for specific stakeholders or interleave the targeted documentation throughout.

Figure 5 - Separate hierarchy

Figure 6 - Interleaved
There are situations where it is impractical to represent cross-cutting interests hierarchically. In these cases what you need is something like an index that allows you to find all the relevant pieces of documentation. Gherkin has a feature called tags that can be used for this purpose.
Stories aren’t features
It is common to see teams create a new feature file for each user story that they implement. I’ve written extensively about why this is a bad idea.
TL;DR – User stories are intended to be used to deliver small increments of functionality. If you create a feature file for each story, then you will expend unnecessary effort maintaining existing feature files. Additionally, feature files created this way will not be useful documentation, because each will only describe a thin slice of functionality.
Conclusion
Of the options provided in this challenge, the winner is the best choice. Personally, I would have chosen Other, because there is more to organising your documentation than simply splitting by functional area.